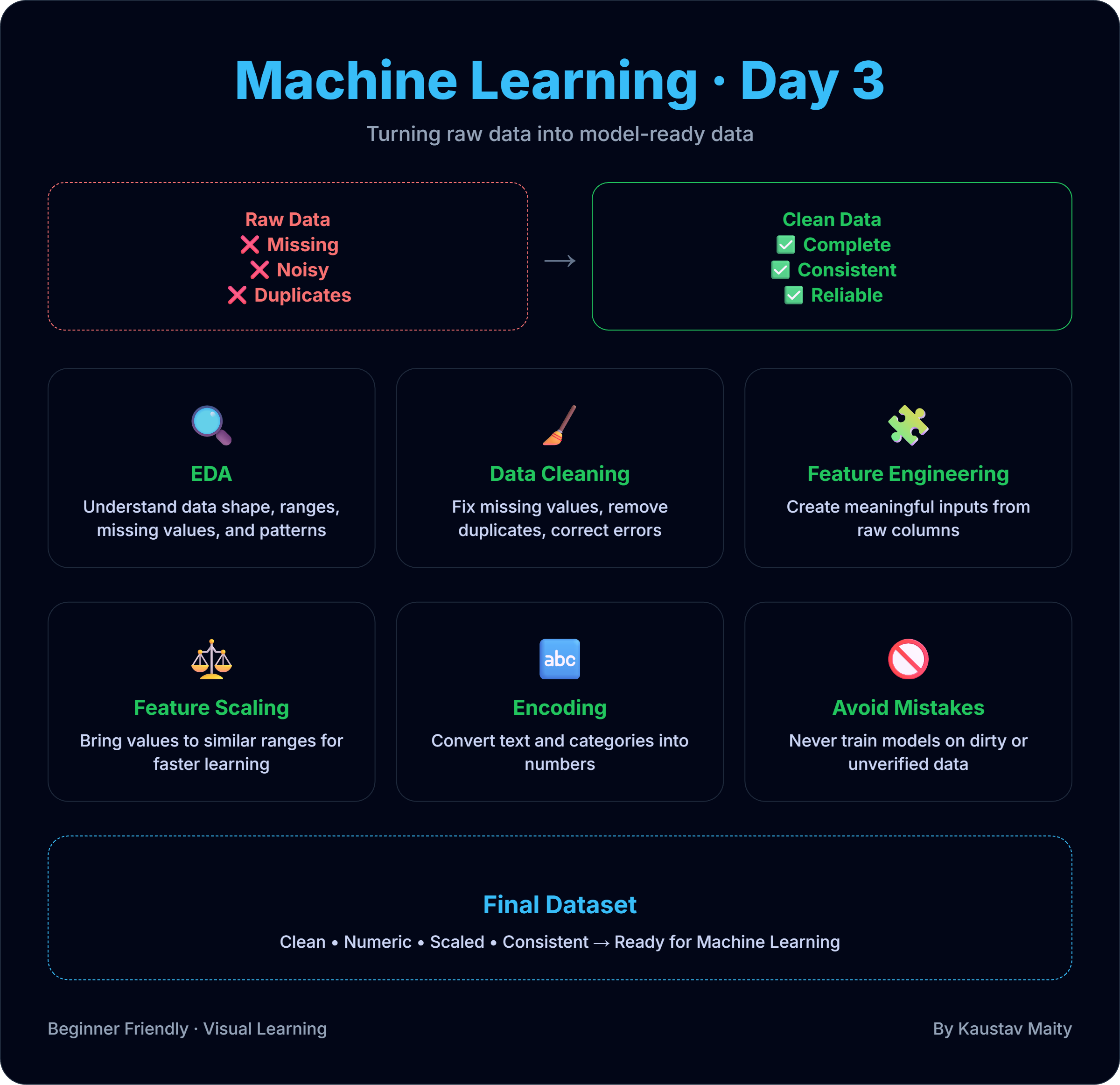
🧹 Day 3: Data in Machine Learning – From Raw Data to Model-Ready Data
If Machine Learning is the engine, then data is the fuel.
And bad fuel will always break a good engine.
In real-world ML projects, 80% of the work is data-related, not algorithms.
This post explains why data matters, what raw data looks like, and how we prepare it for machine learning—in simple, practical terms.
📌 Why Data Is So Important in Machine Learning
Machine Learning models do not understand reality.
They only understand numbers and patterns in data.
If the data is:
- Incomplete ❌
- Noisy ❌
- Biased ❌
Then even the best algorithm will fail.
📌 Good data beats complex models. Always.
📂 What Is Raw Data?
Raw data is data as it comes from the real world, without cleaning.
Examples:
- Missing values
- Duplicate rows
- Incorrect formats
- Outliers
- Text instead of numbers
Example raw dataset (houses):
| Size | Location | Price |
|---|---|---|
| 900 | City | 50 |
| NaN | City | 45 |
| 1200 | ? | 65 |
This data cannot be directly used for ML.
🔍 Step 1: Exploratory Data Analysis (EDA)
Before cleaning data, we must understand it.
EDA answers questions like:
- How many rows and columns?
- Are values missing?
- Are numbers reasonable?
- How is data distributed?
Typical EDA tasks:
- Checking data types
- Finding missing values
- Understanding ranges
- Visualizing distributions
📌 EDA helps you see problems before fixing them.
🧹 Step 2: Data Cleaning
This is where we fix the data.
Common data cleaning tasks:
1️⃣ Handling Missing Values
- Remove rows
- Fill with mean/median
- Use domain logic
2️⃣ Removing Duplicates
- Same record appearing multiple times
3️⃣ Fixing Invalid Data
- Negative prices
- Impossible ages
- Wrong categories
📌 Cleaning makes data usable and trustworthy.
🔄 Step 3: Feature Engineering (Basic)
Features are the inputs to your model.
Feature engineering means:
- Creating new useful columns
- Transforming existing data
Examples:
- Convert date → day, month, year
- Salary per year → salary per month
- Text → numerical representation
📌 Better features = better predictions.
⚖️ Step 4: Feature Scaling
ML models learn faster when numbers are on similar scales.
Example:
- Age: 0–100
- Salary: 10,000–1,000,000
Scaling techniques:
- Normalization (0 to 1)
- Standardization (mean = 0, std = 1)
📌 Scaling prevents one feature from dominating others.
🔤 Step 5: Encoding Categorical Data
Models cannot understand text.
Example:
- City = “Mumbai”, “Delhi”, “Kolkata”
We convert text → numbers using:
- Label Encoding
- One-Hot Encoding
📌 Encoding makes categorical data ML-friendly.
🧠 Final Dataset = Model-Ready Data
After preprocessing, data becomes:
- Clean
- Numeric
- Consistent
- Structured
This is the data you can safely give to a machine learning model.
⚠️ Common Beginner Mistakes
❌ Skipping EDA
❌ Training on dirty data
❌ Ignoring missing values
❌ Not scaling features
📌 Most ML failures come from poor data preparation, not bad models.
📝 Final Thoughts
Machine Learning does not start with algorithms.
It starts with understanding and preparing data.
If you master data:
- Models become easier
- Results improve
- Debugging becomes simpler
Day 3 is about building the most important ML habit:
Respect the data.
Comments (0)
No comments yet. Be the first to share your thoughts!
Leave a Comment