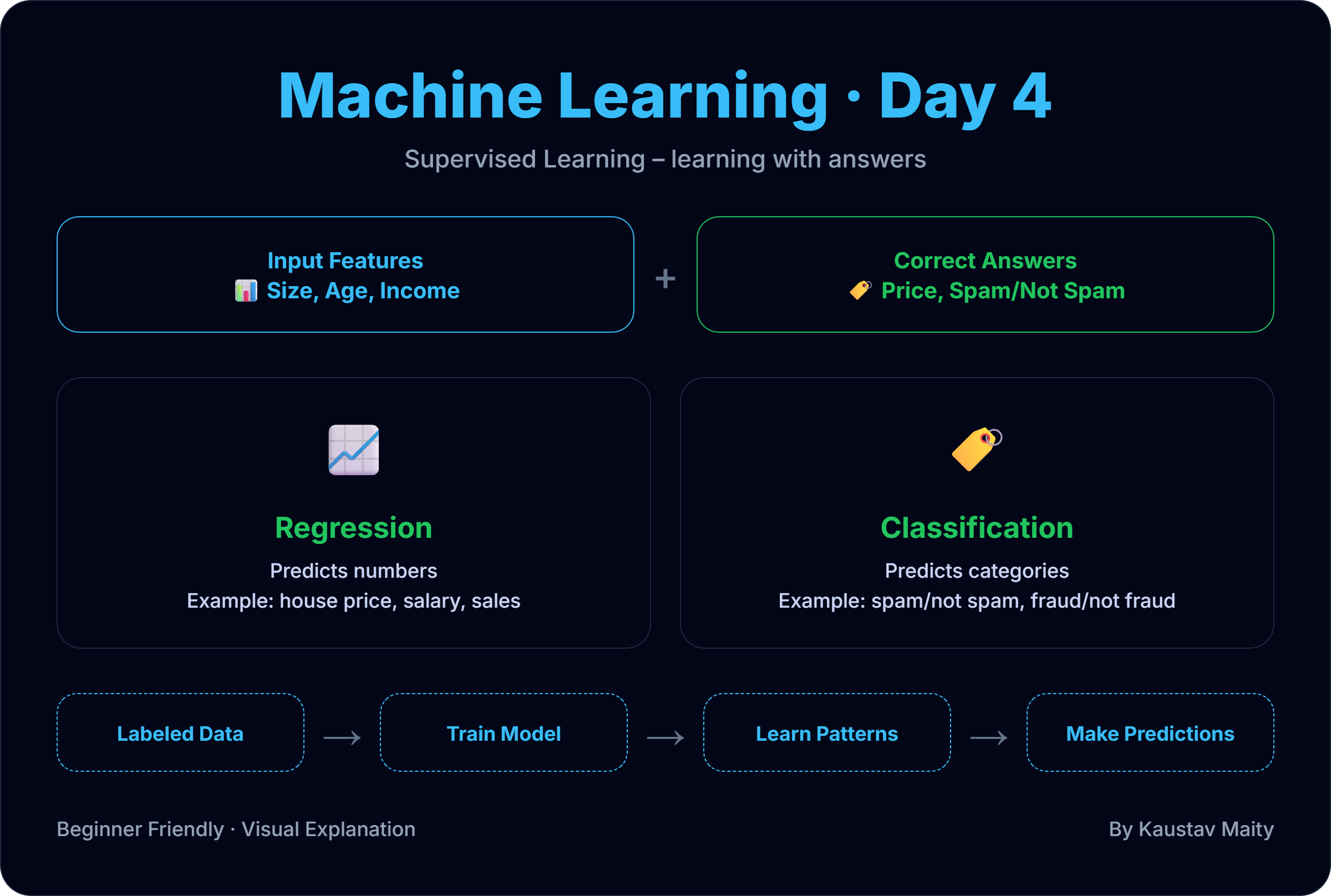
Supervised Learning – Learning with Answers
📘 Day 4: Supervised Learning – Learning with Answers After understanding data and math intuition, it’s time to learn the …
Senior Data Engineer with 5+ years of experience building scalable ETL pipelines, real-time data platforms, and cloud-native solutions on AWS. Passionate about turning complex data challenges into elegant solutions.
Specialized in building robust, scalable data infrastructure on cloud platforms
Building serverless data lakes and ETL pipelines using Glue, Lambda, S3, and EMR.
Processing millions of records with PySpark, optimizing jobs for performance.
5+ years of Python for data processing, automation, and backend services.
Event-driven architectures with Kafka, Kinesis, and streaming pipelines.
Insights and tutorials on data engineering, AWS, and cloud architecture
📘 Day 4: Supervised Learning – Learning with Answers After understanding data and math intuition, it’s time to learn the …
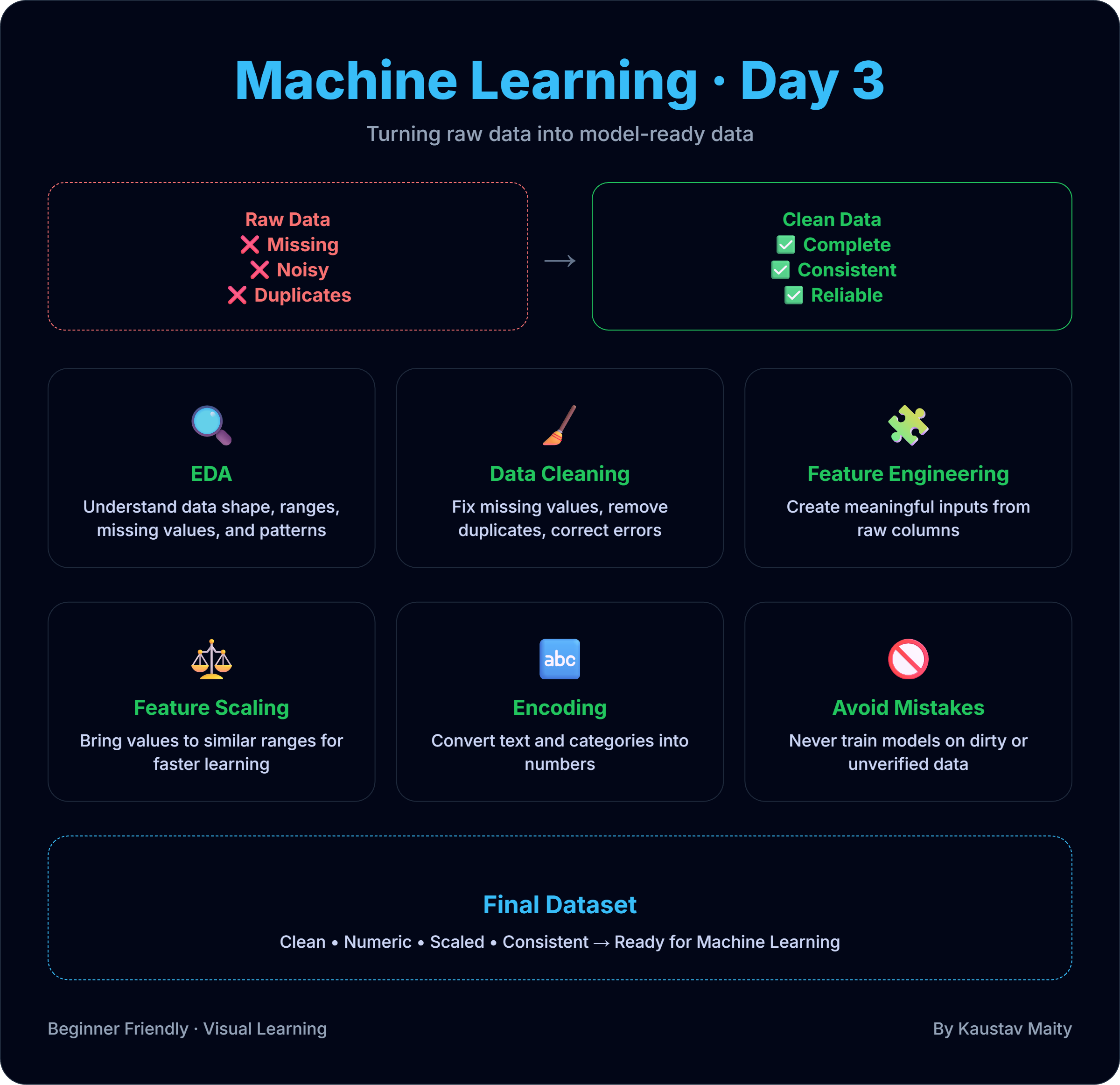
🧹 Day 3: Data in Machine Learning – From Raw Data to Model-Ready Data If Machine Learning is the engine, …
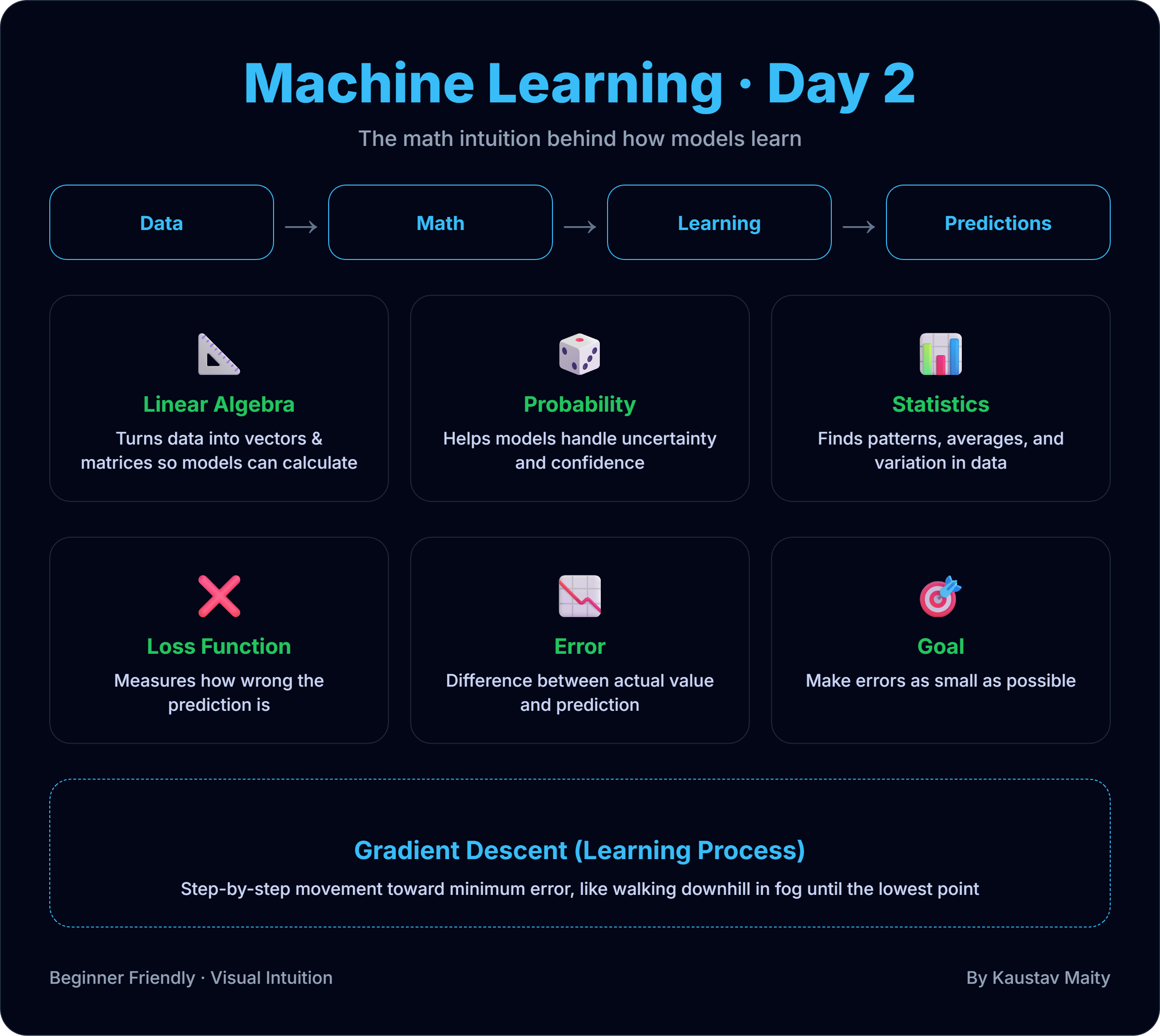
📐 Machine Learning Mathematics: The Intuition You Actually Need (Day 2) Many people feel scared when they hear “Machine Learning …
Have a data engineering challenge? I'd love to help you architect and build scalable solutions that drive real business value.